CSV Parser

The CSV Parser node reads data groups(s) that are CSV formatted from the in port.
Configuration
Basic
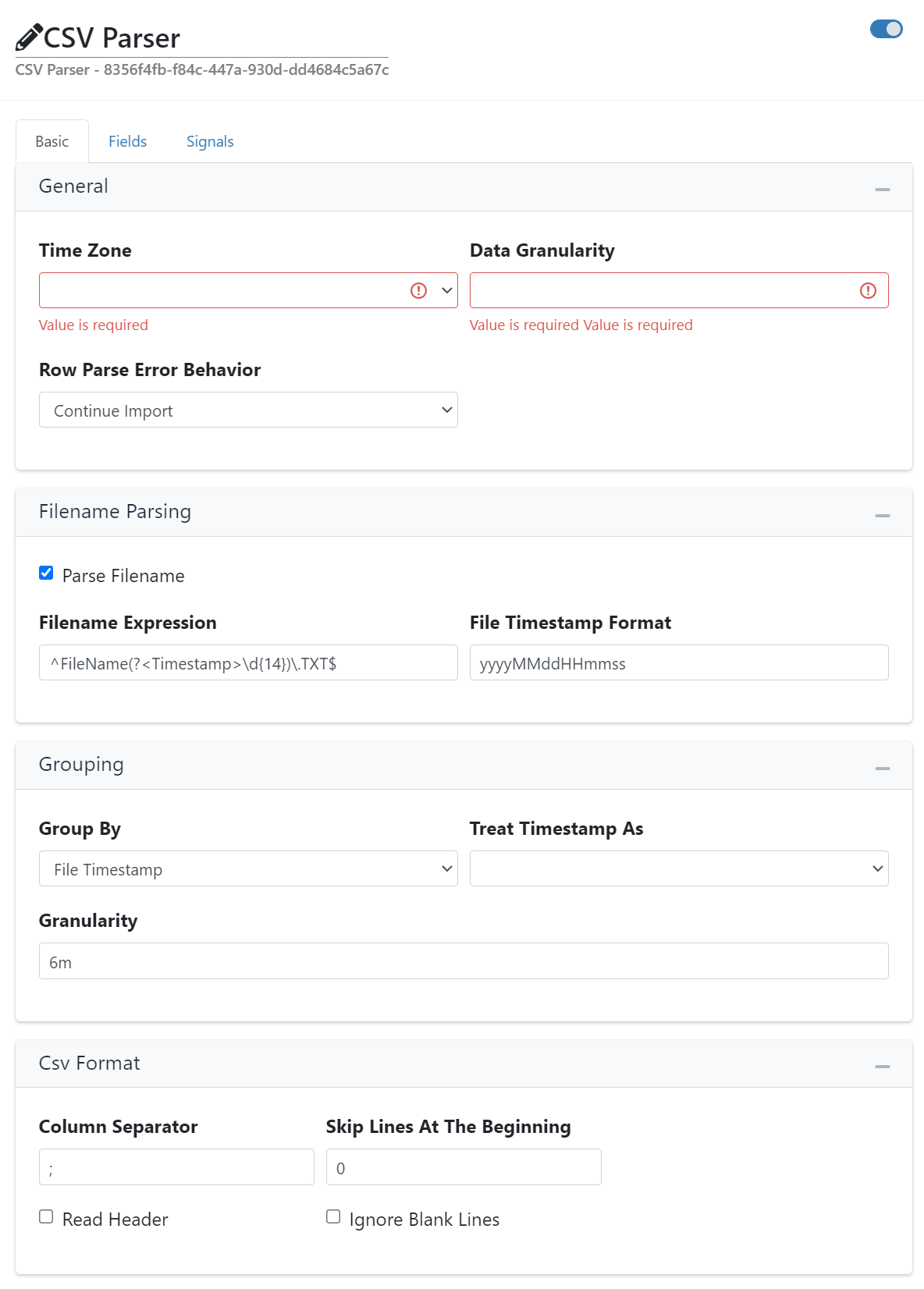
General
- Time Zone
The timezone to be used for writing timestamps.
- Data Granularity
The data granularity of the signals (see Granularity ).
- Row Parse Error Behavior
The behavior of the node when an error occurs while parsing a row.
- Continue Import
Skips the lines with errors and logs a warning with the error.
- Drop Data
Cancels the parsing and logs an error. The file will be send to the binary error port.
Default: Continue Import
Filename Parsing
- Parse Filename
If enabled filename will be parsed using the Filename Expression and the File Timestamp Format.
Default: checked
- Filename Expression
The regular expression for parsing the filename.
Important
It is required to use a capturing group named
Timestampin the regular expression.For an overview of the regular expression language see the Microsoft Docs. The regular expression options
IgnoreCaseandSinglelineare used.Default: ^FileName(?<Timestamp>d{12}).TXT$
- File Timestamp Format
The format to use for parsing the timestamp that has been extracted from the filename. For formatting the timestamp value see Standard date and time format strings and Custom date and time format strings.
Default: yyyyMMddHHmm
Grouping
- Group By
This parameter specifies how the data in the file is grouped into one or more data groups.
- File Timestamp
All data in the file is in one datagroup, the grouping timestamp is the one that has been extracted from the filename.
- Granularity
The data is grouped using the specified Group By Granularity and aligning the timestamps according to the Group By Granularity Mode
- Monthly
One data group per month will generated
Default: File Timestamp
- Treat Timestamp As
This determines how the timestamps are aligned when
Granularityis used for the Group By Timestamp parameter.- Use Start
Uses the exact or previous valid timestamp for the specified Group By Granularity
- Use End
Uses the exact or next valid timestamp for the specified Group By Granularity
- Granularity
This specifies the granularity of how the timestamps are aligned when
Granularityis used for the Group By Timestamp parameter (see Granularity ).Default: 6m
CSV Format
- Column Separator
The character used to separate the columns.
Default: ;
- Skip Lines At The Beginning
The number of lines to skip in the file before parsing starts.
Default: 0
- Read Header
If enabled a header names will be read from the file and used for field selection.
Default: disabled
- Ignore Blank Lines
If this option is enabled, empty lines in the file will be skipped.
Default: disabled
Fields
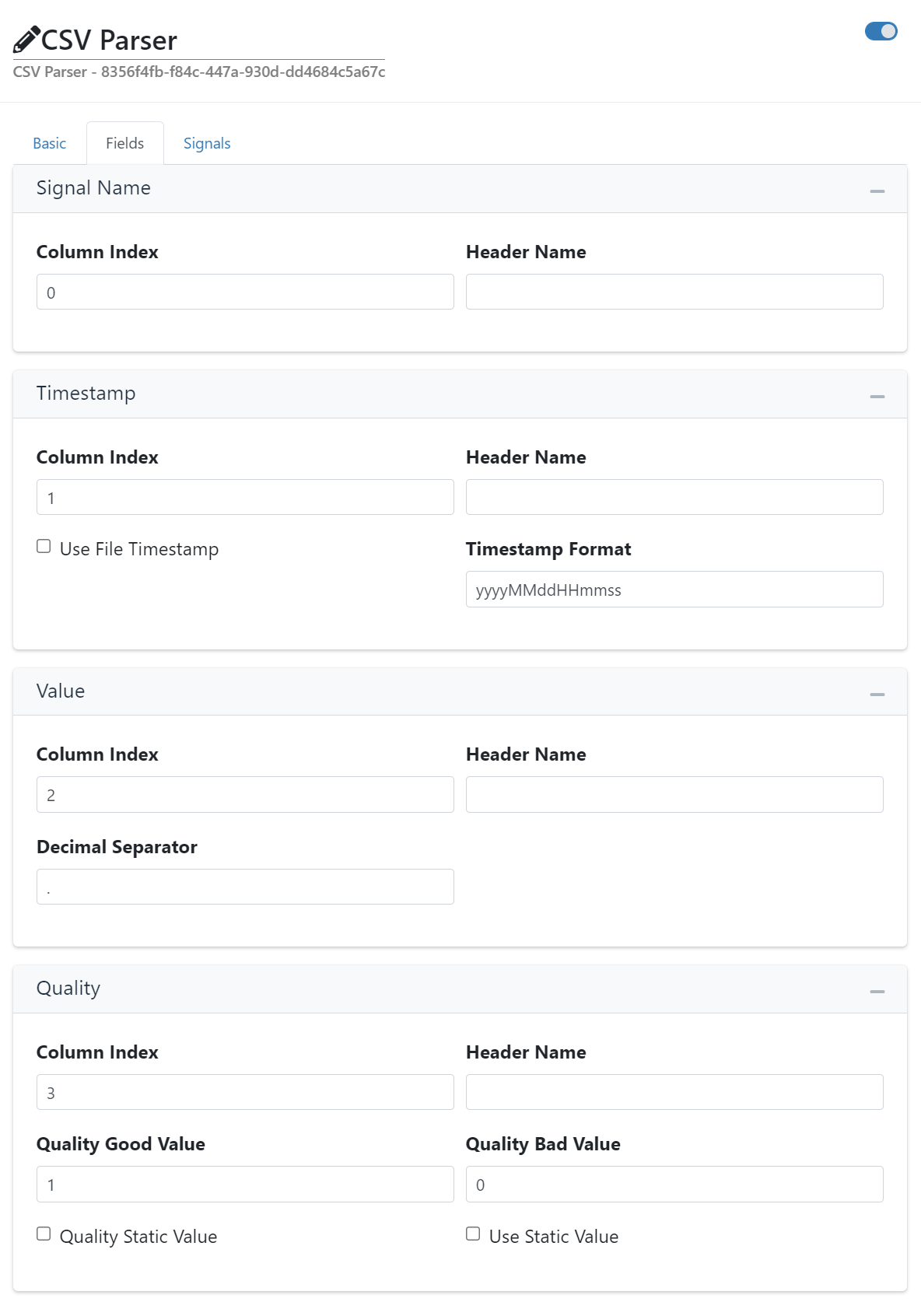
Here you can specify the columns to be written file using the Enabled parameter. The order of the columns can be changed by setting the Column Index.
Signal Name
This specifies how to read the name of the signal.
- Column Index
The zero based column index in the CSV file.
Default: 0
- Header Name
The name of the header to match Read Header is enabled.
Timestamp
This specifies how to read the timestamp of the datapoint.
- Column Index
The zero based column index in the CSV file.
Default: 1
- Header Name
The name of the header to match Read Header is enabled.
- Use File Timestamp
If enabled use the timestamp that was extracted from the filename for the datapoints.
Warning
This option is currently not implemented.
Default: disabled
- Timestamp Format
The format to use for writing timestamps. For formating the timestamp value see Standard date and time format strings and Custom date and time format strings.
Default: yyyyMMddHHmmss
Value
This specifies how to read the value of the datapoint.
- Column Index
The zero based column index in the CSV file.
Default: 2
- Header Name
The name of the header to match Read Header is enabled.
- Decimal Separator
The character used as the decimal point when writing numeric values.
Default: .
Quality
This specifies how to read the quality of the datapoint.
- Column Index
The zero based column index in the CSV file.
Default: 3
- Header Name
The name of the header to match Read Header is enabled.
- Quality Good Value
The string that indicates that the quality is good.
Default: 1
- Quality Bad Value
The string that indicates that the quality is bad.
Default: 0
- Quality Static Value
If the option Use Static Value is activated, this value (activated = good, deactivated = bad) is used for the quality.
Default: disabled
- Use Static Value
If enabled the Quality Static Value will be used for the quality.
Default: disabled
Signals
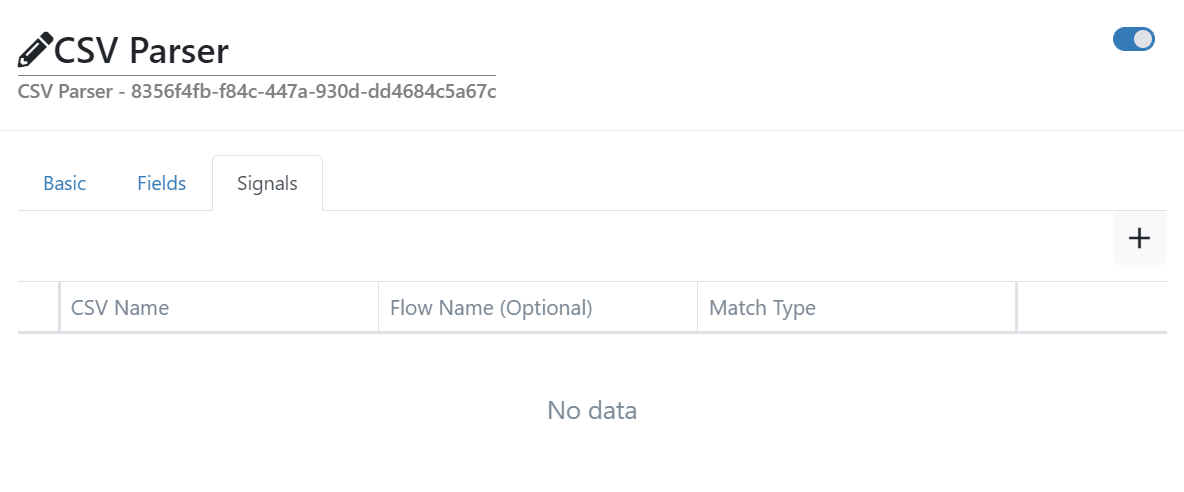
Define the signals to read from the CSV file.
- CSV Name
The name of the signal in the file.
- Flow Name (Optional)
The name of the signal in the outgoing data group. If this field is empty the Flow Name is the same as the CSV Name.
- Match Type
The name of the signal in the incoming data group.
- Full Name
Matching the incoming signal name with the CSV Name.
- Wild Card
Matching the incoming signal name with the CSV Name allowing wildcards (
*and?).- Regular Expression
Matching the incoming signal name with a regular expression specified in the CSV Name. For an overview of the regular expression language see the Microsoft Docs. The regular expression options
Singlelineare used.
Default: Full Name