CSV Source
Danger
This node is deprecated. Do not use this node for new flows.
As a replacement use a combination of [Interval Trigger] –> [File System Source] –> [CSV Parser]
The CSV Source node reads data groups(s) that are CSV formatted from a folder on the computer where the node is running.
The format of the CSV file must be:
<signal name>;<timestamp>;<value>;<quality>
No header is allowed.
A quality of 1 will be interpreted as good, all other values are bad.
Configuration
Basic
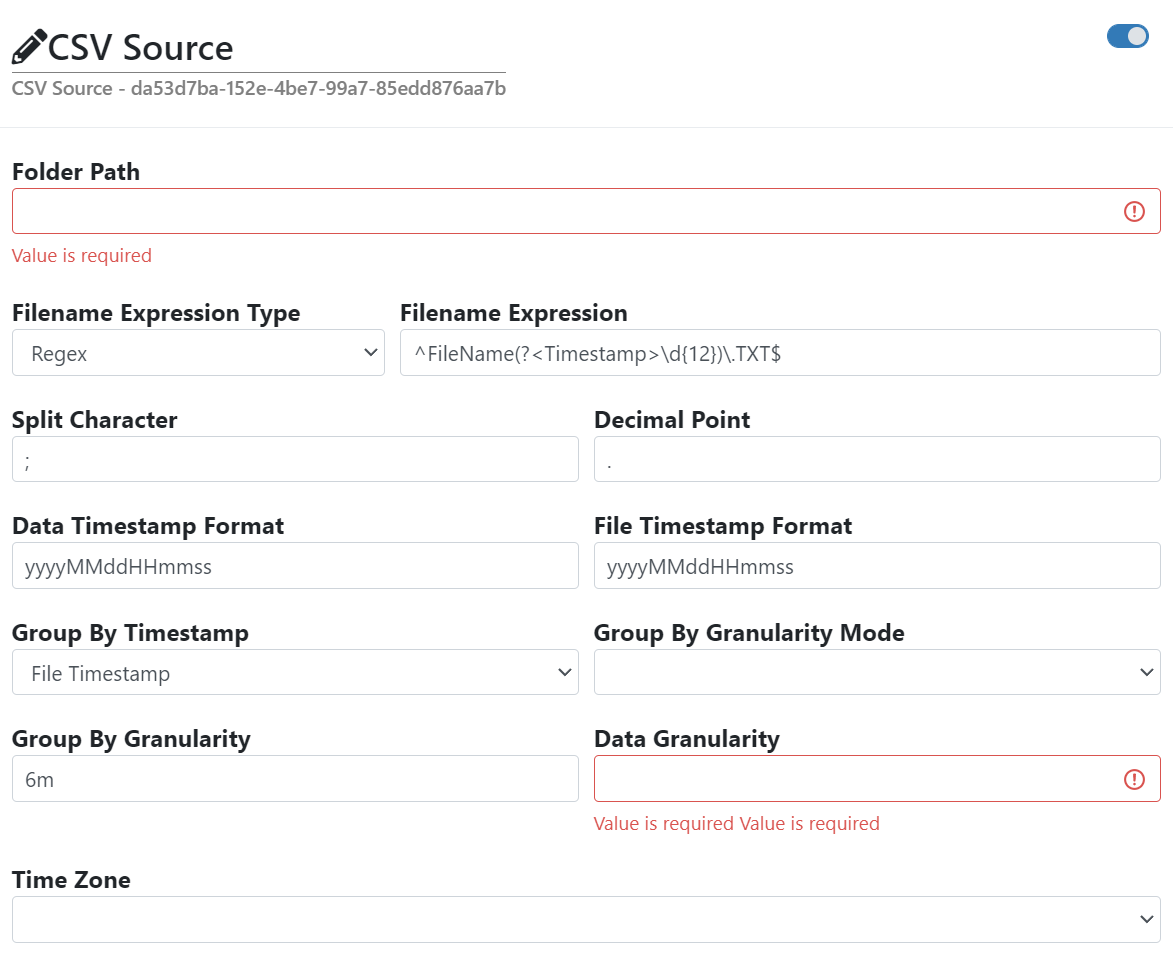
- Folder Path
The folder on the computer where the node is running from where the data will be retrieved.
- Filename Expression Type
The type of the filename expression.
- Regex
This type allows a regular expression to be used as the search pattern.
Important
If the option
File Timestampshould be used for parameter Group By Timestamp it is required to use a capturing group namedTimestampin the regular expression.For an overview of the regular expression language see the Microsoft Docs. The regular expression options
IgnoreCaseandSinglelineare used.- Wildcard
This type allows a combination of valid literal path and wildcard (
*and?) characters to be used in the search pattern.Warning
No timestamp will be extracted from the file name so the option
File Timestampwill not be available for parameter Group By Timestamp
Default: Regex
- Filename Expression
The search pattern that selects which files will be retrieved.
Default: ^FileName(?<Timestamp>d{12}).TXT$
- Split Character
The character used to separate the columns in the CSV file.
Default: ;
- Decimal Point
The character used as the decimal point when parsing numeric values in the CSV file.
Default: .
- Data Timestamp Format
The format to use for parsing timestamps. For formatting the timestamp value see Standard date and time format strings and Custom date and time format strings.
Default: yyyyMMddHHmm
- File Timestamp Format
The format to use for parsing the timestamp that has been extracted from the filename. For formatting the timestamp value see Standard date and time format strings and Custom date and time format strings.
Default: yyyyMMddHHmm
- Group By Timestamp
This parameter specifies how the data in the file is grouped into one or more data groups.
- File Timestamp
All data in the file is in one datagroup, the grouping timestamp is the one that has been extracted from the filename.
- Granularity
The data is grouped using the specified Group By Granularity and aligning the timestamps according to the Group By Granularity Mode.
- Monthly
One data group per month will generated
Default: File Timestamp
- Group By Granularity Mode
This determines how the timestamps are aligned when
Granularityis used for the Group By Timestamp parameter.- Use Start
Uses the exact or previous valid timestamp for the specified Group By Granularity
- Use End
Uses the exact or next valid timestamp for the specified Group By Granularity
- Group By Granularity
This specifies the granularity of how the timestamps are aligned when
Granularityis used for the Group By Timestamp parameter (see Granularity ).Default: 6m
- Data Granularity
The data granularity of the signals (see Granularity ).
- Time Zone
The timezone to be used for reading timestamps.